



Завантажити сьогоднішній матеріал файлом можна тут.
Регулярні вирази (regular expressions) Ruby (скорочено ruby regex) допомагають знаходити певні шаблони всередині рядків з метою вилучення, зміни або просто перевірки даних для подальшої обробки.
Два поширені випадки використання регулярних виразів включають перевірку(валідацію) та синтаксичний аналіз(парсинг). Наприклад:
Якщо говоримо про адресу електронної пошти, то за допомогою регулярного виразу ruby ви можете визначити, як виглядає дійсна адреса електронної пошти. Іншими словами, ваша програма зможе відрізнити дійсну та недійсну адресу електронної пошти.
Регулярні вирази Ruby визначаються між двома похилими рисками, щоб відрізняти їх від синтаксису іншої мови. Найпростіші вирази можуть співпадати зі словом або навіть однією літерою.

Це повертає індекс першого співпадіння слова, якщо воно було знайдено (успішний збіг), або nil в іншому випадку. Якщо нам не важливий індекс, ми можемо використати String#include? метод.
Інший спосіб перевірити, чи збігається рядок з регулярним виразом, — це використати метод match:
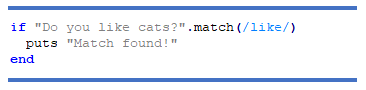
Ви дізнаєтесь, як створювати більш розширені шаблони, щоб ви могли зіставляти, фіксувати та замінювати такі речі, як дати, номери телефонів, електронні адреси, URL-адреси тощо.
Клас символів дає змогу визначити діапазон або список символів для відповідності. Наприклад, [aeiou] відповідає будь-якій голосній.
Приклад: чи містить рядок голосну?
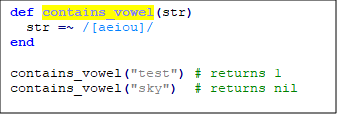
При цьому не враховуватиметься кількість символів; ми побачимо, як це зробити незабаром.
А за допомогою такого варіанту можна «фільтрувати» слова з масиву в яких є такий збіг такого формату /cot|cut/ чи /c(o|u)t/:
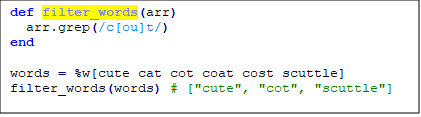
Давайте трішки поясню, що тут відбувається. Тут я спочатку створив метод з назвою filter_words та параметром arr. Метод grep просто порівнює дві речі за допомогою ===. Тобто він бере по черзі кожен елемент масиву і перевіряє чи відповідає даний об’єкт написаному регулярному виразу (шаблону). Після того я оголошую наповнений масив (назва words) з певними String об’єктами. І останній крок: я викликаю метод filter_words якому передаю попередньо оголошений масив, який повертає відфільтрований масив.
Ми можемо використовувати діапазони (ranges) для зіставлення кількох літер або цифр без необхідності вводити їх усі. Іншими словами, такий діапазон, як [2-5], такий самий, як [2345].
Деякі корисні діапазони:
Приклад: чи містить цей рядок числа?
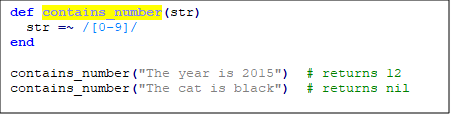
Існує гарний скорочений синтаксис для визначення діапазону символів:
Існує також заперечна форма цього:
Символ крапки. відповідає всьому, крім нових рядків. Якщо вам потрібно використовувати літерал . тоді вам доведеться екранувати його.
Якщо ми не заекрануємо спеціальний символ (крапку), тоді буква буде «проходити» наш шаблон і це погано - буде не той результат, який ми очікували б.

В цьому ж випадку лише варіант з крапкою пройде:
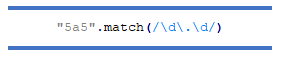
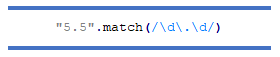
Дотепер ми могли збігатися лише з одним символом за раз. Щоб зіставити кілька символів, ми можемо використовувати модифікатори шаблонів.
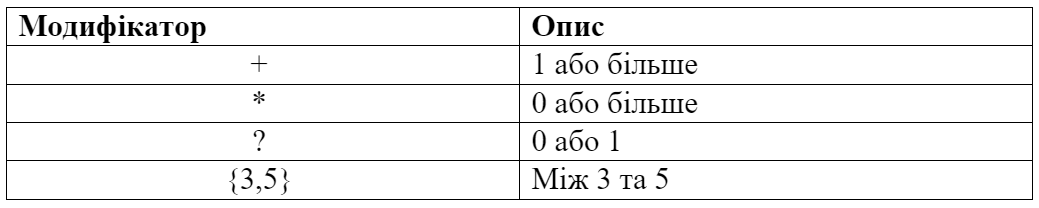
Ми можемо об’єднати все, що навчилися до цих пір, щоб створити більш складні регулярні вирази.
Приклад: це схоже на IP-адресу?
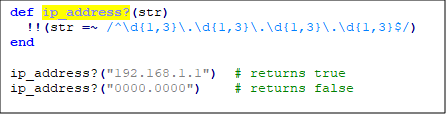
Ми використовуємо !! щоб перетворити значення, що повертається, на логічне (true або false)
Зверніть увагу, що по даному шаблону також збігатиметься деяка недійсна IP-адреса. Як 999.999.999.999, але в цьому випадку нас цікавить лише формат.
Якщо вам потрібні точні збіги, вам знадобиться інший тип модифікатора. Давайте розглянемо приклад, щоб ви могли зрозуміти, про що я говорю:
Ми хочемо дізнатися, якщо цей рядок містить рівно чотири літери, тоді він мав би пройти, але в даному випадку даний рядок все одно збігатиметься, при тому, що він має більше чотирьох літер, але це не те, що ми хочемо.

Замість цього ми будемо використовувати модифікатори «початок рядка» та «кінець рядка».

Цього разу не збігається, тобто те, що ми й хотіли. Це досить надуманий приклад, оскільки ми могли просто використати метод .size, щоб знайти довжину, але я думаю, що цей приклад передає суть ідеї.
Щоб відбувалася перевірка збігу лише на початку рядка, а не на кожному рядку (після \n), вам потрібно використовувати \A та \Z замість ^ та $.
За допомогою груп захоплення ми можемо захопити частину matcher-a та використати його пізніше. Щоб зафіксувати збіг, ми беремо ту частину, яку хочемо захопити, у дужки.
Приклад: Синтаксичний аналіз (парсинг) файлу журналу
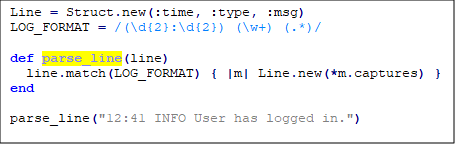
У цьому прикладі ми використовуємо .match замість =~.
Цей метод повертає об’єкт MatchData, якщо є збіг, або nil в іншому випадку. Клас MatchData має багато корисних методів.
Якщо вам потрібне лише логічне значення (true / false), тоді ви можете використовувати match? метод. Це також швидше працює, ніж match, оскільки Ruby не потрібно створювати об’єкт MatchData.
Ви можете отримати доступ до отриманих даних за допомогою методу .captures або розглядаючи об’єкт MatchData як масив, нульовий індекс матиме повний збіг, а наступні індекси міститимуть відповідні групи.
Якщо вам потрібна перша група захоплення, ви можете зробити це:
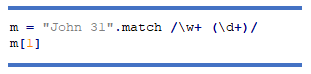
Ви також можете мати групи без захоплення. Вони дозволять групувати вирази разом без погіршення продуктивності. Ви також можете знайти іменовані групи корисними для полегшення читання складних виразів.

Приклад: група з назвою
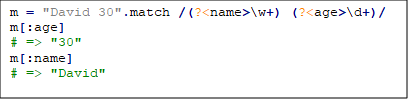
Група з назвою повертає об’єкт MatchData, до якого можна отримати доступ, щоб отримати результати.
Регулярні вирази Ruby є екземплярами класу Regexp. Здебільшого ви не будете використовувати цей клас безпосередньо, але це корисно знати 🙂
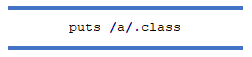
Одним із можливих способів використання є створення регулярного виразу з рядка:
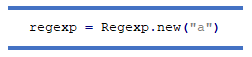
Інший спосіб створити регулярний вираз:
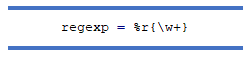
Складні регулярні вирази Ruby може бути досить важко читати, тому буде корисно, якщо ми розіб’ємо їх на кілька рядків. Ми можемо зробити це за допомогою модифікатора «x». Цей формат також дозволяє використовувати коментарі у вашому регулярному виразі.
Приклад:

Регулярні вирази можна використовувати з багатьма методами Ruby:
Приклад: відібрати всі «підходящі» слова з рядка за допомогою .scan

Приклад: вилучення всіх чисел із рядка:

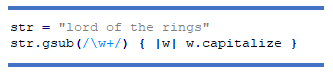
Приклад: зробити усі слова в рядку з великої літери:
Приклад: перевірити адресу електронної пошти:
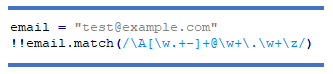
Цей останній приклад використовує !! щоб перетворити результат у логічне значення (true/false) або ж можна використати метод match?
Регулярні вирази дивовижні, але іноді вони можуть бути трохи складними. Використання деяких онлайн інструментів може допомогти вам створити регулярні вирази більш інтерактивним способом. Також ці сервіси містять шпаргалку регулярних виразів Ruby, яка буде для вас дуже корисною. Тому рекомендую для навчання такі онлайн редактори:
А також офіційна документація по Regexp:
Завантажити сьогоднішній матеріал файлом можна тут.
P.S. Продовження за посиланням
Група в телеграмі: https://t.me/ruby4you
Автор курсу: Шкоропад Даниїл
![]()




